An Introduction to Parallelizing Tests with Cider-CI
Cider-CI enables you to parallelize tests without limits achieving speedups from several hours to a few minutes. We guide through the process from configuring a not parallelized test, over manual parallelization, to configure automatic parallelization with Cider-CI in this article.
- updated: 2016-07-24
- created: 2015-12-12
- level: basic, intermediate
- keywords: parallel testing
Table of Contents
- Background
- Basic Project Configuration
- Splitting Tests Manually
- Splitting Tests Automatically
- Where To Go From Here
Background
We recapture the basic entities jobs, tasks, and executor in Cider-CI as far as they relate to parallelization. The coarsest entity in Cider-CI is the job. A project might have multiple jobs and a typical one will run all the tests.
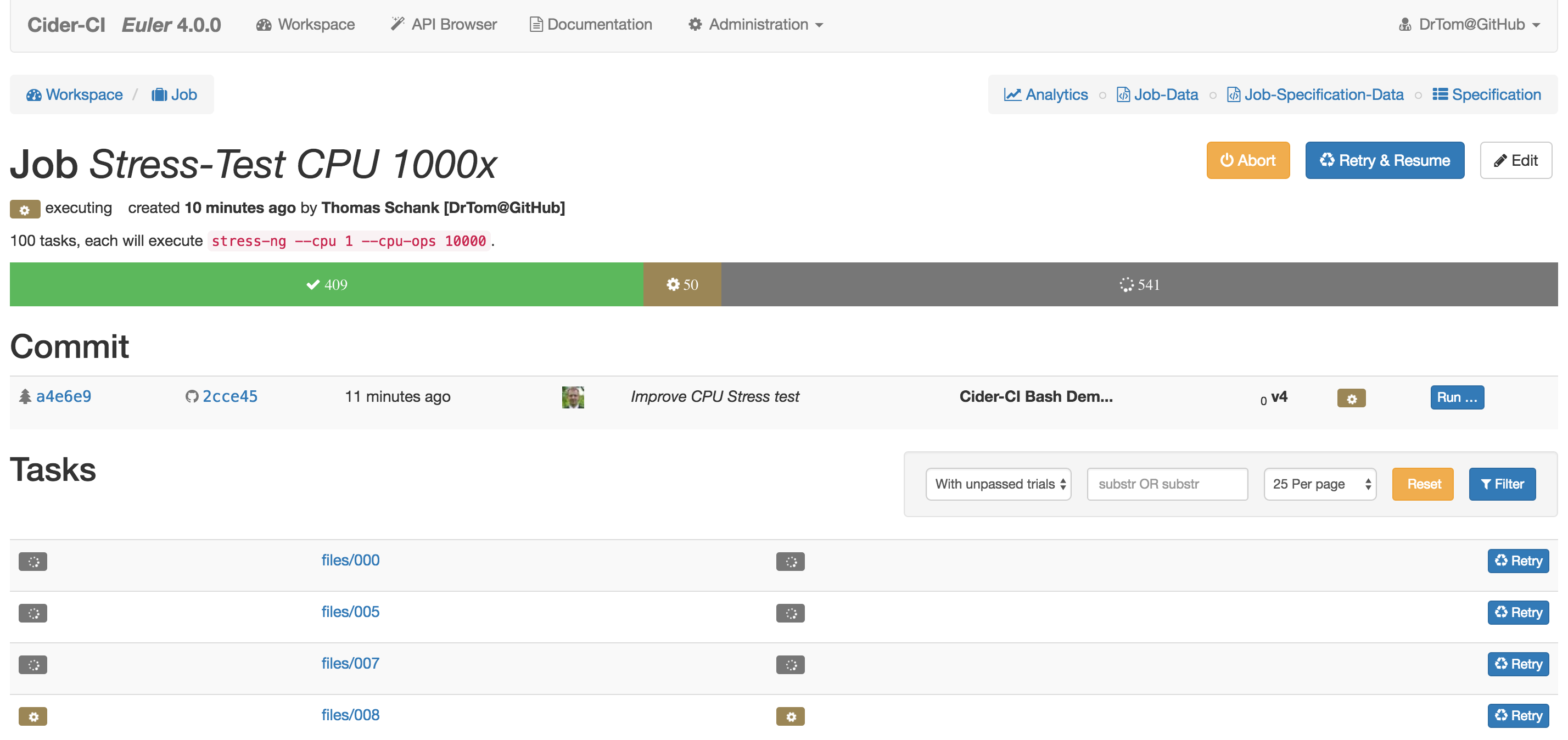
A job is a container for at least one but potentially any number of tasks. Every task embodies a unit of execution. They are dispatched to available executors independently from each other. The job will then aggregate the outcome of all tasks. This is the foundation of parallelization in Cider-CI.

The screenshot shows a job being executed. From a total of 1000 tasks, 409 have passed, and 50 are being executed currently in parallel.
Basic Project Configuration
In Cider-CI the project configuration is always part of the source
code1. Jobs are declared in the configuration file cider-ci.yml.
The example shows a very simple job with one tasks. The body of the tasks is
formulated with some trickery to pass on Linux like and Windows operating
systems.
jobs:
single-task-demo:
task: |
:; exit 0
exit /b 0
The previous job formulation above uses the "compact notation". Cider-CI will always convert declarations into a "canonical form". Additional options are available when we write the project configuration directly in the "canonical form". You can read more about the compact notation in the Cider-CI documentation.
This example is similar to the previous one but it sets the timeout
property explicitly.
Let us focus on the tasks property. This is where parallelization comes into
play if we list more than one task, see the next section. The content of the
tasks is a map which models a collection. Cider-CI favors maps instead of
arrays because they enable composability.
jobs:
single-task-demo:
context:
tasks:
task1:
scripts:
main:
body: |
:; sleep 299 && exit 0
timeout 299
exit /b 0
timeout: 5 Minutes
Splitting Tests Manually
The next step in parallelization is to define multiple tasks according to the capabilities of the used test runner. In the case of RSpec it is possible to specify directories, files, and even parts of test files. Most testing frameworks support similar capabilities, either directly or via a described one-to-one relation between filename and test classes, e.g. in the case of JUnit.
jobs:
rspec-tests:
name: RSpec Tests
tasks:
feature-tests:
name: RSpec Feature Tests
body: rspec spec/features
controller-tests:
body: rspec spec/controllers
model-tests:
body: rspec spec/models
Splitting Tests Automatically
Splitting tests based on files is in particular appealing and Cider-CI has a built-in directive to achieve this in a dynamic manner, i.e. without listing the tasks explicitly in the configuration file.
The directive generate_tasks honors the include_match and exculude_match
properties. The values are converted to regular expression
patterns2. Then every file committed to the source code is
matched against them and included if and only if include_match matches but
exclude_match does not.
The main part of the task configuration is located in the task_defaults.
Every task generated in this context inherits the properties from the
task_defaults. The important part is that the body evaluates the
environment variable CIDER_CI_TASK_FILE which holds the dedicated path to the
file for every tasks.
jobs:
rspec-tests:
name: RSpec Tests
description: |
This job will run every `_rspec.rb`
file in its own task.
task_defaults:
body: rspec $CIDER_CI_TASK_FILE
generate_tasks:
include_match: spec/.*_spec.rb
The output of this expansion looks very much as if the tasks would have been
generated manually. With the difference that each task itself contains merely
the definition of the CIDER_CI_TASK_FILE. The evaluation is governed by what
is defined in the task_defaults.
jobs:
rspec-tests:
name: RSpec Tests
description: |
This job will run every `_rspec.rb`
file in its own task.
task_defaults:
body: rspec $CIDER_CI_TASK_FILE
tasks:
spec/features/explore_spec.rb:
environment_variables:
CIDER_CI_TASK_FILE: spec/features/explore_spec.rb
⋯
Where To Go From Here
The Advanced Topics section of the Cider-CI documentation leads to content describing the project configuration and transformation in detail.
-
Cider-CI values reproducibly very highly and this is a consequence. ↩
-
Precisely, they are converted into a
java.util.regex.Patternviare-pattern. ↩